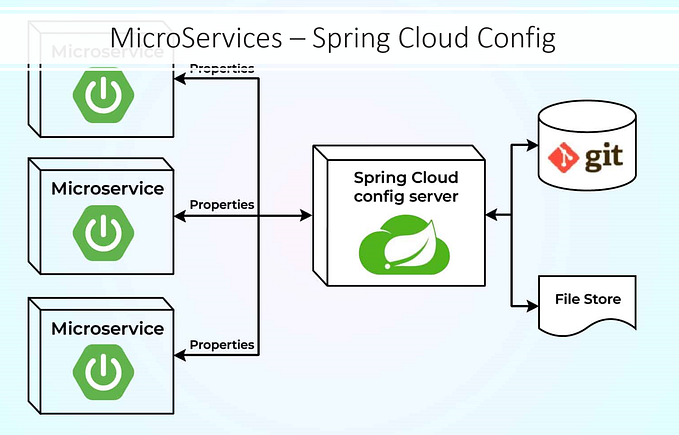
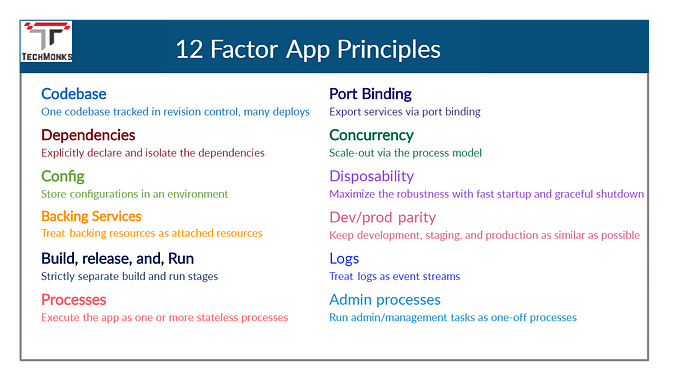
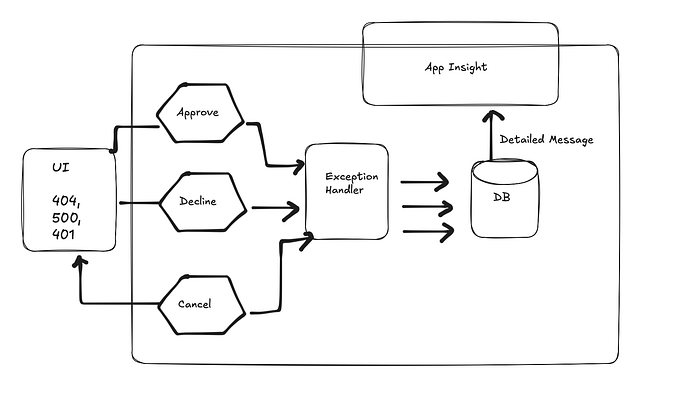
Multiple services work together in microservice ecosystems to solve business problems. As each service is focused on a single independent responsibility, it may require collaboration with other microservices using synchronous or asynchronous channels. As this communication happens over the network, it is paramount to ensure every microservice adopts self-healing capabilities.
Before delving into Self-healing, let us understand what self-healing is.
Self-healing refers to the ability of a system/component to automatically detect, recover from, and mitigate failures or disruptions without human intervention. The goal is to maintain system stability, minimize downtime, and ensure seamless user experiences, even when individual components fail or encounter issues.
In Microservices, self-healing plays an integral role in maintaining system stability, minimizing downtime, and reducing operational overhead associated with manual recovery and monitoring processes.
Key aspects of Self-Healing
- Failure Detection: The system continuously monitors itself to detect failures or anomalies. This can be done by monitoring error rates, latency metrics, health checks, logs, and other metrics for real-time detection. Tools like Elastic APM, App Dynamics, and Grafana can help you monitor the metrics and trigger the alerts and self-healing mechanisms.
- Automated Recovery: Once a failure is detected, the system automatically attempts to recover without manual intervention. Mechanisms like auto-restarting failed services, rerouting traffic, or retrying failed operations.
- Fault Isolation: Preventing system failures from propagating to other services. Mechanisms like circuit breakers and bulkheads isolate the affected service or component.
- Graceful Degradation: When full recovery isn’t immediately possible, the system provides limited functionality or alternative solutions to maintain usability. For example, serving cached data when the primary service is unavailable.
- Proactive Resilience: Anticipating potential failures and addressing them before they occur. Includes practices like chaos engineering to test and improve recovery mechanisms.
Implementing Self-healing in Microservices
Below are a few key aspects that can be considered to enable self-healing in your microservice ecosystem.
- Health Checks: Enable periodic health checks to ensure services are running as expected. Kubernetes uses liveness and readiness probes to restart unhealthy containers or stop routing traffic to them.
- Retry and backoff: Automatically retry failed operations with delays (backoff) to handle transient errors.
- Circuit Breakers: Temporarily stop calls to a failing service to prevent overloading and allow it time to recover.
- Bulkhead: implement Bulkhead to isolate failures and prevent them from cascading through the entire system. bulkheads create isolation between components or parts of the system, ensuring that failures or resource exhaustion in one area do not affect the others.
- Timeouts: Implement timeouts to prevent indefinite waits while communicating with the upstream systems. This improves the user experience and helps maintain system stability and resource efficiency.
- Auto-Scaling: Automatically add or remove instances of a service based on current demand or load.
- Dead Letter Queues (DLQs): Capture unprocessed messages from a message queue for later inspection or retry.
- Chaos Engineering: Injecting failures intentionally (e.g., errors/timeouts/shutting down instances) to test the system’s resilience and ability to self-heal.
- Service Mesh and Sidecars: Service meshes like Istio provide automated traffic routing, retries, and failover mechanisms.
Benefits of Self-healing
- Business Continuity: Self-healing enables you to protect critical business functions from being disrupted by technical failures. Ensures adherence to SLAs, maintaining customer trust and satisfaction.
- Improved User experience: Minimizes service disruptions and ensures that the user's experience is consistent and reliable.
- Increased System Availability: Ensures services remain operational and accessible even when individual components fail. Reduces downtime by quickly detecting and recovering from failures.
- Reduced Operational Costs: Automates repetitive and error-prone recovery tasks, reducing the workload for operations teams. Lowers the cost of incident management and manual troubleshooting.
- Fault Isolation: Prevents failures in one service or component from cascading to other parts of the system. Mechanisms like circuit breakers and bulkheads localize issues, protecting the overall ecosystem.
- Faster Recovery: Automated recovery mechanisms reduce the time it takes to restore normal operations after a failure. Eliminates the reliance on manual intervention, enabling quicker resolution.
Self-healing is a cornerstone of building robust, scalable, and resilient microservice architectures, making systems more reliable and capable of handling unexpected issues gracefully.
That’s all for today!
Thank you for taking the time to read this article. I hope you have enjoyed it. If you enjoyed it and would like to stay updated on various technology topics, please consider subscribing for more insightful content.