AI Fundamentals: Building an AI powered Conversational Chatbot using Open AI Chat GPT APIs and Python
Artificial Intelligence (AI) has revolutionized various industries, and one of its most exciting applications is in the development of chatbots. In this blog post, we will explore how to create a simple Conversational ChatBot by leveraging the capabilities of OpenAI’s Chat GPT API.
By the end of this tutorial, you will have a solid understanding of the fundamentals of AI chatbot development and be equipped with the knowledge to build your own functional chatbot using OpenAI’s powerful language model. So let’s dive in.
Prerequisites:
- Basic understanding of Python
- Open AI Account and API key to connect to Chat GPT
Initial Setup: Please ensure you have Python installed on your machine. You can verify the version of Python using the command ‘python -V`. This will give you the currently installed Python version.
Please create an account if you do not have one with Open AI and generate the API key. Once you create the account, please navigate here to generate the API keys
Install the OpenAI libraries
Please execute the below command to install the openai libraries.
pip install openaipip is a package manager for Python, like npm for Node.
Prior to creating the sample Python script to connect to Chat GPT through APIs, let us understand a few key concepts that help us understand the API integration in a much better manner.
Model
In layman's terms, a Model is a program or algorithm that depends on the trained data to analyze the datasets and find patterns to make predictions. The AI model's goal is to replicate human intelligence in the most effective way.
The OpenAI API is powered by a diverse set of models with different capabilities and price points. You can also make limited customizations to our original base models for your specific use case with fine-tuning.
Below are the models offered by the Open AI

You can find more information about the models here
Tokens
Tokens are the basic unit that the Open AI models use to compute the length of a text. Tokens are characters that align with words, but not always. In particular, it depends on the number of characters and includes punctuation signs or emojis. This is why the token count is usually different from the word count.
Temperature
The temperature parameter affects the imagination and creativity of the output from Open AI models. Model responses are indeterministic/non-predictable. It means that you will get a slightly different response every time you call the API. A lower temperature will result in more predictable output, while a higher temperature will result in more random output. The temperature value varies from 0.0 to 1.0. You can make the responses predictable by setting the parameter temperate to 0. i.e., if you send a query to Chat GPT with the temperature value of ‘0’, you will get the same response.
Messages
Open AI APIs expect prompts to be a collection of messages. Each message comprises role and content keys and fields. The accepted values for the role are ‘user’, ‘assistant’, or ‘system, and the content is the actual message (a.k.a. prompt).
The role ‘user’ represents the one who gives the instructions, and the ‘system’ or ‘assistant’ role specifies the context. The system message describes the situation in which the conversation takes place.
Example:
messages: [
{"role":"system", "content":"Act as a python expert and answer the student queries"},
{"role":"user", "content": "what is scope in Python?"}
]Python script to connect to Chat GPT through Open APIs
Below is the basic Python script to connect to the Chat GPT and get the response to our queries.
import openai
openai.api_key = "sk-*******************"
messages = []
#Append the message to the conversation history
def add_message(role, message):
messages.append({"role": role, "content": message})
def converse_with_chatGPT():
model_engine = "gpt-3.5-turbo"
response = openai.ChatCompletion.create(
model=model_engine, #Open AI model name
messages=messages, # user query
max_tokens = 1024, # this is the maximum number of tokens that can be used to provide a response.
n=1, #number of responses expected from the Chat GPT
stop=None,
temperature=0.5 #making responses deterministic
)
# print(response)
message = response.choices[0].message.content
return message.strip()
# process user prompt
def process_user_query(prompt):
user_prompt = (f"{prompt}")
add_message("user", user_prompt)
result = converse_with_chatGPT()
print(result)
#Request user to provide the query
def user_query():
while True:
prompt = input("Enter your question: ")
response = process_user_query(prompt)
print(response)
user_query()The above code is self-explanatory. Let us take a closer look at the Open AI Chat Completion API parameters.
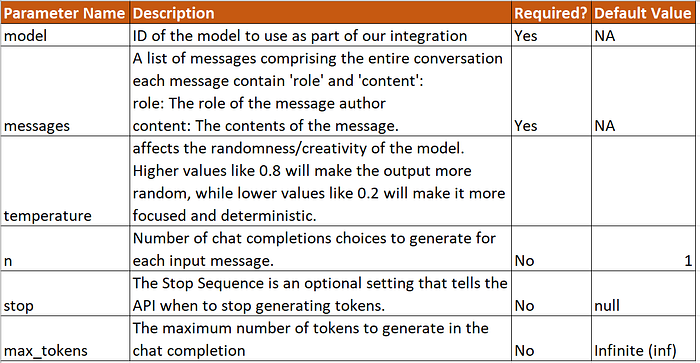
You can find more details about the Chat Completion API here.
Let us run the application and verify the results.

From the above image, you can see our script could connect to Chat GPT and get the results.
Conversational Queries with Open AI APIs
Let us ask a follow-up question like ‘repeating the answer for our previous query’ and see how Chat GPT responds.
Surprisingly, below is the response from the Chat GPT.
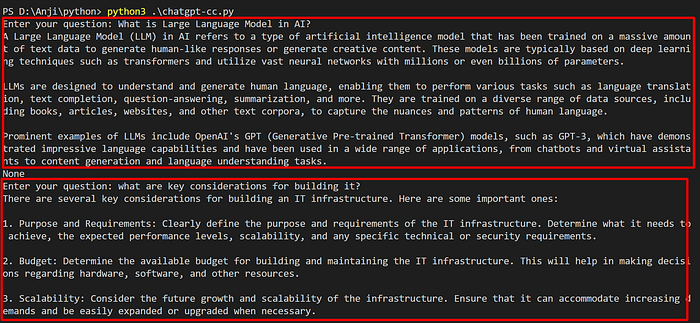
The above response has no relation to our previous question. i.e., Chat GPT doesn’t maintain the context for the queries that we are asking through APIs (stateless). As each request is treated as a unique request, you explicitly need to manage the context.
To manage the context, multiple queries in a conversation, you need to send the previous query responses to the Chat GPT. Let us modify our Python script to manage the context and get the responses from Chat GPT.
import openai
#Please add your open AI API key here.
openai.api_key = "sk-***************"
#messages to store the conversation
messages = [
]
#Append the message to the conversation history
def add_message(role, message):
messages.append({"role": role, "content": message})
#Trigger the Open AI APIs
def converse_with_chatGPT():
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo", #Open AI model name
messages=messages, # user query
max_tokens = 1024, # this is the maximum number of tokens that can be used to provide a response.
n=1, #number of responses expected from the Chat GPT
stop=None,
temperature=0.5 #making responses deterministic or not much imaginative
)
# print(response)
message = response.choices[0].message.content
add_message("assistant", message)
return message.strip()
# process user prompt
def process_user_query(prompt):
user_prompt = (f"{prompt}")
add_message("user", user_prompt)
result = converse_with_chatGPT()
print(result)
#Request user to provide the query
def user_query():
while True:
prompt = input("Enter your question: ")
response = process_user_query(prompt)
print(response)
# Call user_query to start conversation with user
user_query()The above code is self-explanatory. If you have any queries regarding the code, please feel free to mention them in the comments.
Let us run the script and start a conversation with Chat GPT.
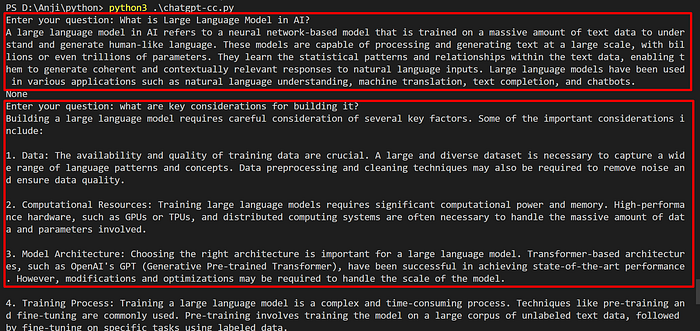
You can observe that the context is being managed between the conversations now, and the Chat GPT is answering our queries in a conversational way.
You can find the complete source code on GitHub
Thank you for taking the time to read this article. If you enjoyed it and would like to stay updated on various technology topics, please consider subscribing for more insightful content.